Semantic SEO has been covered all over the web by those far smarter than myself.
That said, I feel a lot of content on semantic search, entities, and topical authority is either:
- Oversimplified (and sometimes inaccurate)
- Just a little over the head of a noob like me (which is fine)
So I wanted to lay out what I hope is a little more accessible introduction to semantic search, while staying true to the complexities involved.
But first, if you want more of a deep dive, check out:
- Medium End: Semantic SEO Guide – Dixon Jones
- Slightly Deeper: Importance of Topical Authority: Semantic SEO Case Study – Koray Tuğberk GÜBÜR
- The Deep End: All of Bill Slawski’s Posts Related to Semantic SEO
What Is Semantic Search?
Semantic search is a search engine’s effort to uncover the underlying meaning of a page. Put simply, rather than matching a search to a page by counting the number of times a keyword is used, semantic search examines the underlying topic at hand and the intent of the search.
To help you grasp the idea here, the opposite of semantic search might involve matching a query to a page based solely on how many times the phrase was used on the page, regardless what the page was actually about.
In a non-semantic world, if you searched for “why should I take apple cider vinegar” you would likely get a page with that exact phrase plastered all over it. Note that the top result here doesn’t have exact text of the query anywhere on the page.
But thanks to countless technologies, Google understands what the searcher is looking for by analyzing:
- The topic / entity (apple cider vinegar)
- The search intent (why should I take it)
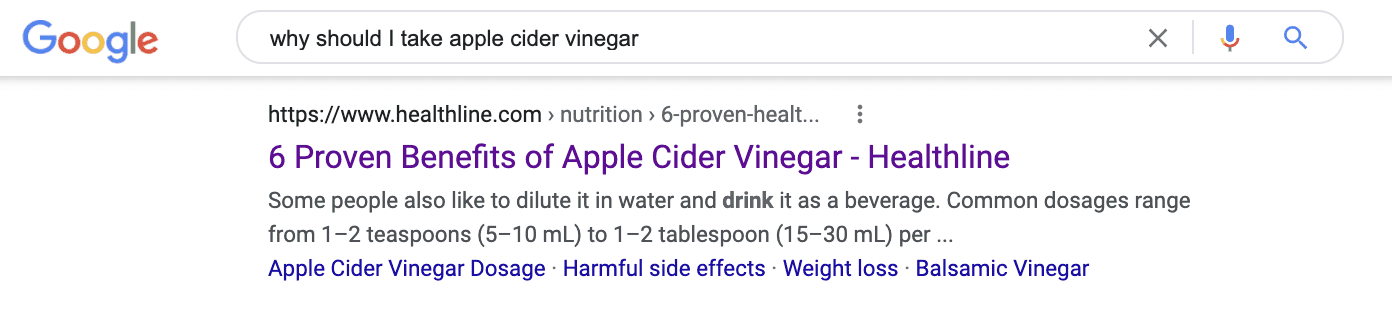
The Healthline article has taken the “angle” of benefits, which Google correctly matches to the searcher’s intent.
Let’s look at another example of semantic search in action:
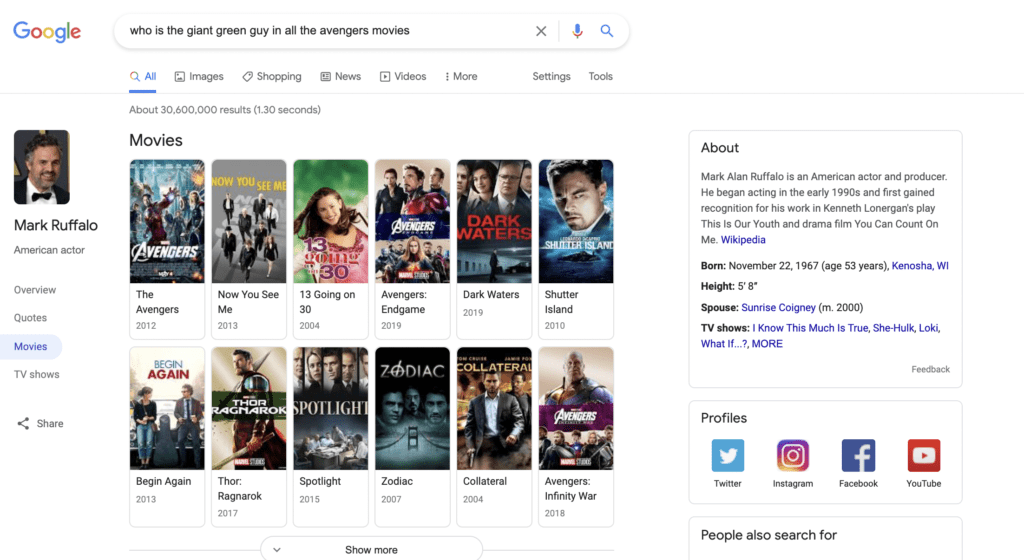
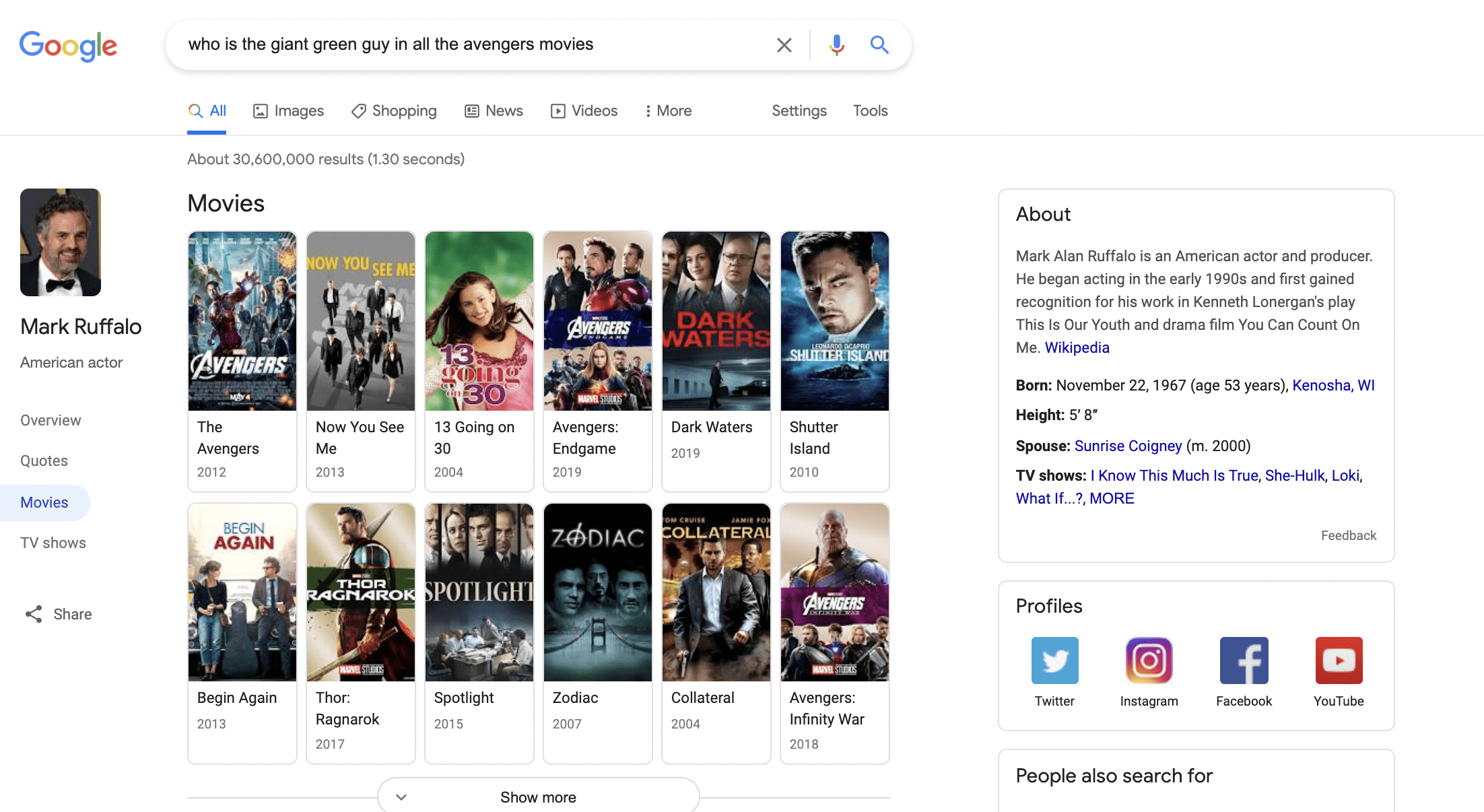
When you search “who is the giant green guy in all the avengers movies,” Google returns a knowledge panel (along with a fancy lefthand sidebar – pretty new as of early 2021) for Mark Ruffalo. Now I know we’re all used to this by now, but take a step back and realize how impressive that is.
Google was able to connect the dots between “green guy” and “avengers” to give us Mark Ruffalo, despite us not mentioning him or The Hulk by name. This can be largely attributed to Google’s Knowledge graph.
Understanding Entities and the Knowledge Graph
To understand semantic search well, we need to understand entities. Put really simply, entities are just things (or objects) – a person, place, thing, concept, or idea. In our examples above, apple cider vinegar, Mark Ruffalo, and The Hulk are all entities. Entities help Google understand the web.
But often, relationships between entities are even more important for search.
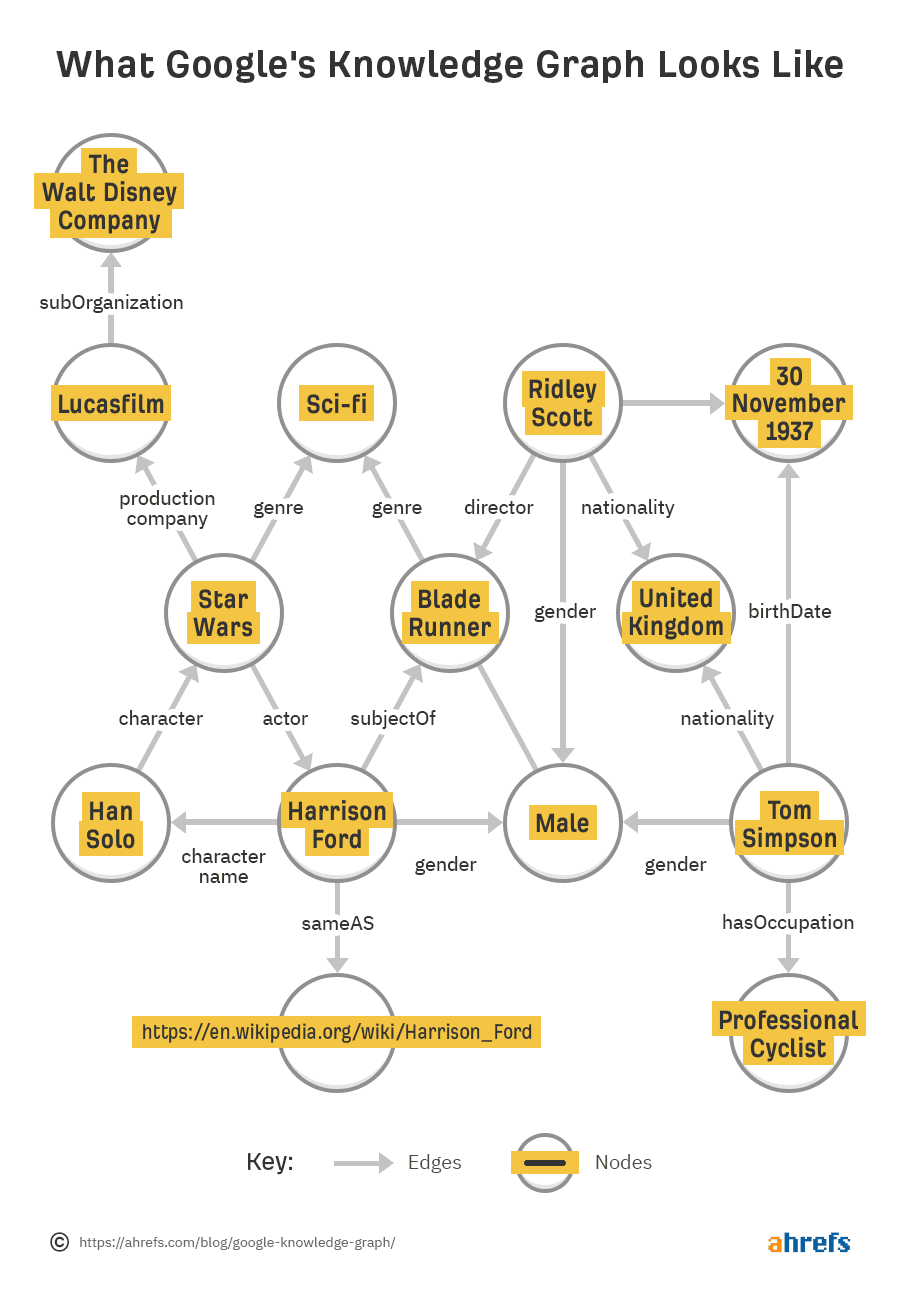
In order to organize entities and their relationship with each other, Google uses what’s called the Knowledge Graph. An entity exists on a “node,” and its relationship to another entity is referred to as an “edge.”
Let’s look at the search “who is the president” (searched from a U.S. IP address) to better understand the knowledge graph and entities.
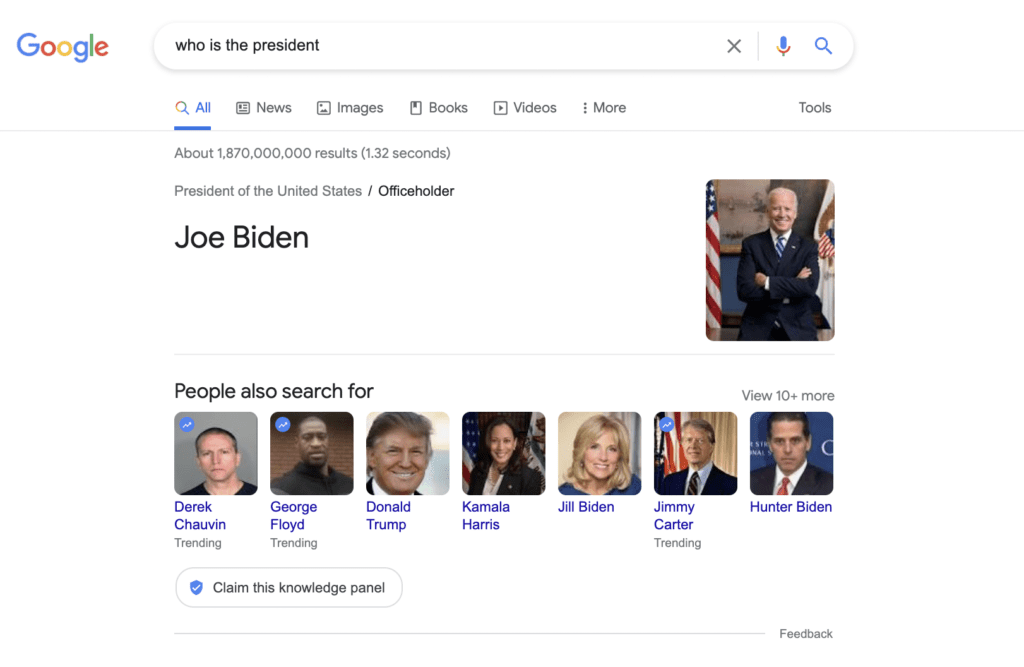
Similar to our Hulk search above, we get a snippet with Joe Biden.
It’s clear from the snippet that Google associates Joe Biden with the office of the President of the United States. These are both known entities within the Knowledge graph connected by the edge “officeholder.” Officeholder itself isn’t an entity, but it defines the connection between the two.
Note that “president” itself isn’t a known entity, and that there are different presidents around the world. We didn’t search “President of the United States,” right? So how did Google know what to serve us?
Google recognizes the term “president,” as a synonym for the entity “President of the United States” thanks to our search being made in the US.
So how does Google know those two entities are related? How do they construct the knowledge graph? We don’t know for certain (it’s not documented explicitly), but we have some strong theories:
- We believe Wikipedia is used as a highly trusted source for the knowledge graph. If there’s a Wikipedia page for it, it’s likely a known entity. And if there’s not a Wikipedia page for something, it’s probably not an entity. But that doesn’t mean it’s not a topic Google understands well.
- It’s likely Google uses some more advanced version of Latent Semantic Indexing and co-citation. Put in an oversimplified way: If certain words are frequently used alongside other words throughout the web (like “president” and “Biden”), Google can assume there’s a correlation.
- I’d also imagine Google uses search data and user data to confirm connections. If the majority of searches for “Alphabet” result in clicks on articles about “Google,” they’re probably related. (Whether or not they use CTR as a ranking factor is a different conversation.)
How important are entities when it comes to SEO? Some believe Google has already (or will soon) move away from mobile-first indexing focused first and foremost on URLs to entity-first indexing focused first and foremost on entity hierarchy according to the knowledge graph.
Cindy Krum goes into awesome detail on this in her blog series.
How Did We Get Here? Semantic Technologies in Google’s Algorithm
I mentioned that there are hundreds (thousands? idk) of technologies at work in semantic search. Let’s look just a few big algorithm updates and a couple technologies that have paved the way. Note: this list isn’t even close to exhaustive.
- Brandy (2004): Brandy introduced LSI (latent semantic indexing). LSI is a method of analyzing a set of documents that keys in on the occurrence of words that appear together in order to better understand a word’s meaning – it helped Google understand the difference between a saw horse and a live horse by looking at similar words used around each. It’s pretty unlikely Google uses LSI in today’s algorithm, but more advanced technologies that have taken the concept further.
- Knowledge Graph (2012): The introduction of the knowledge graph was a big step forward in semantic search. The knowledge graph is made up of entities and their relationship to each other. It helped turn Google’s understanding of “Dallas Cowboys” from a combination of two distinct words into a single entity (a football team). Google engineer Amit Singhal said, “[The Knowledge Graph is an] intelligent model that understands real-world entities and their relationships to one another: things, not strings.”
- Penguin (2012): The Penguin update focused primarily on link schemes and keyword stuffing, introducing technologies that sought to better understood the content and meaning of pages, rather than simply rewarding the page with the most instances of a certain keyword.
- Hummingbird (2013): Hummingbird was big for semantic search. Google described it as a complete overhaul of the core algorithm. Moz says Hummingbird took semantic search from a concept to reality. Its biggest hallmark was a heightened focus on intent through query rewriting. Rather than matching queries to keywords, Hummingbird focused on matching search context to results. “Where to get tacos” now gives you a far different SERP than “how to make tacos.” Now you can target multiple keywords with one page.
- RankBrain (2015): If Hummingbird enhanced semantic search, RankBrain put it on steroids through machine learning. RankBrain looks at additional factors like the location of the searcher, search history, and the words of the query to better determine a searcher’s true intent and deliver even more relevant results.
- BERT (2019): The introduction of BERT, a technology called Bidirectional Encoder Representations from Transformers (and other, similar technologies), took search intent and conversational search to a new level – particularly with a focus on previously “less important words” like conjunctions and their placements in the query. For instance, prior to BERT, a query like “brazil traveler to usa need a visa” likely wouldn’t have placed enough emphasis on the word “to” and given you US-centric results rather than help for a Brazilian. Now, the intent is better understood, giving us more helpful SERPs. Whether or not BERT itself dramatically impacted search, we now know that NLP (Natural Language Processing) technologies are being used in a big way.
Semantic SEO Strategies
So what does semantic search mean for SEO strategies? I won’t go into too much detail here, but will introduce some popular strategies for ranking based on semantic search:
- Get a Wikipedia listing – read how from Dixon Jones
- Use structured data – get an intro from Moz if you’re not familiar
- Build topical clusters – read how from HubSpot
- Optimize your internal linking strategy around topics – read how from this case study
- Write with Semantic SEO in mind – read how from SEJ
- Check out Google’s NLP Demo
Semantic Search Isn’t Going Anywhere
I want to reiterate that semantic search isn’t new – Google has always used aspects of semantic search in their algorithms. But it has come a very long way in the last twenty years.
And it’s not going anywhere.
If you aren’t familiar with entities, Natural Language Processing, schema, and similar terms – and you do SEO for a living – it’s time to start digging in.
And if you feel like it’s a bit too in the weeds and want some help implementing some helpful tactics on your site, get in touch with an SEO expert. I’d be happy to help.
Quick PR Note: Brooks Manley Marketing has been selected among the Top New Orleans SEO Companies by DesignRush.